
1. RAG의 본질과 가치
- LLM은 정보를 학습(1)하거나 외부로부터 가져와 활용(2)할 수 있습니다.
- (1) Fine-tuning: 가중치 업데이트
- (2) RAG: 관련 문맥을 프롬프트로 주입 → 최신 정보/사실 기반 응답에 효과적
- 특히 엔터프라이즈 데이터에서 정확한 사실 회상에 RAG는 강력한 접근법
2. RAG 향상 기법
| Base RAG | 문서 청크 임베딩 후 Top-K 검색 | LangChain vectorstores |
| Summary Embedding | 요약 임베딩 검색 후 원문 전달 | LangChain Multi Vector Retriever |
| Windowing | 청크 검색 후 확장 영역 반환 | LangChain Parent Document Retriever |
| Metadata Filtering | 메타데이터 기반 필터링 검색 | Self-query retriever |
| Embedding Fine-tune | 임베딩 모델 자체를 커스터마이징 | LangChain Fine-tuning |
| 2-Stage RAG | 키워드 기반 1차 → 의미기반 2차 | Cohere Re-rank |
3. Multi-Vector Retriever 핵심 전략
문서의 검색용 요약과 응답용 원문을 분리
- 예: 문서 요약은 벡터 검색에 최적화하고, LLM에는 전체 문서를 주입
- 텍스트뿐 아니라 표(Table)와 이미지(Image)에도 동일 전략 적용 가능

4. 문서 유형별 Cookbook 요약
1) Semi-Structured (Text + Tables)
- 표 데이터를 자연어 요약으로 변환 후 임베딩
- 질문과 의미적으로 유사한 요약이 검색되면 → 원본 표 전체를 LLM에 전달
- 사용 도구: Unstructured + Multi-vector Retriever
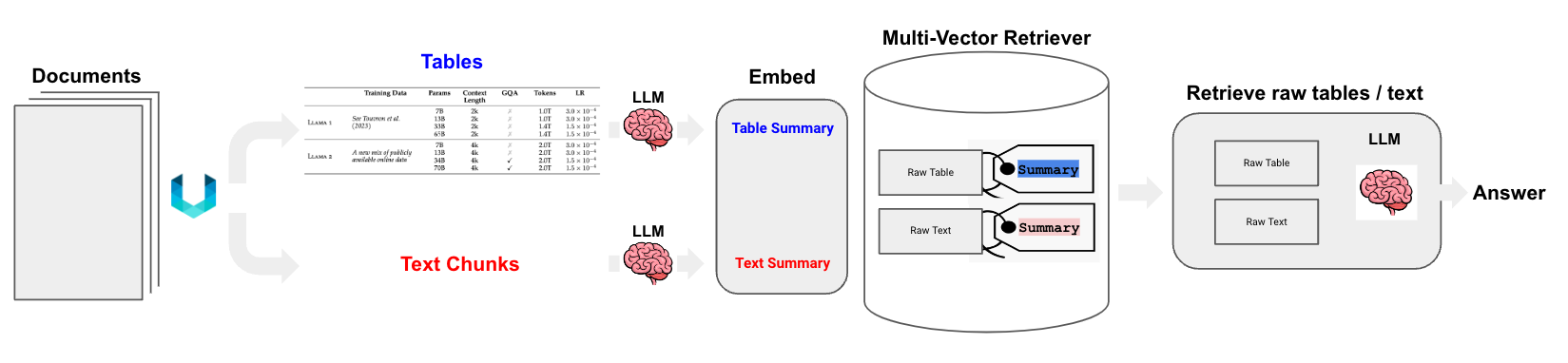
2) Multi-modal (Text + Tables + Images)
이미지도 포함하는 경우 세 가지 접근 방식 제시
| Option 1 | CLIP 등으로 이미지와 텍스트 공동 임베딩 → 이미지 경로만 링크해 LLM에 전달 |
| Option 2 | LLM으로 이미지 요약 텍스트 생성 → 텍스트 임베딩 → 텍스트만 LLM에 주입 |
| Option 3 | 이미지 요약 → 임베딩 → 이미지와 텍스트 모두 LLM에 전달 |
3) Private Multimodal RAG (로컬 실행)
- 전체 파이프라인을 로컬 머신에서 실행 가능한 버전
- 구성 요소:
- 이미지 요약: LLaVA 7B
- 벡터 검색: Chroma
- 임베딩: Nomic GPT4All
- LLM: LLaMA2-13b-chat (via Ollama.ai)

출처 : https://blog.langchain.dev/semi-structured-multi-modal-rag/
728x90
'공부하는삶 > CV' 카테고리의 다른 글
| [TIL] Emerging Properties in Self-Supervised Vision Transformers (0) | 2025.02.04 |
|---|---|
| [TIL] Segmentation fault (core dumped) (0) | 2024.05.24 |
| [TIL] CVAT 설치하기 (0) | 2023.12.22 |
| [TIL] 영상을 탐지한 후, BBOX에 한글을 출력하기 (0) | 2023.12.06 |
| pycocotools 설치 에러 (0) | 2023.08.29 |
| OpenCV 저장 영상 웹 재생시 코덱 문제 (0) | 2023.08.29 |